After installing 3 new hosts, I kept getting errors for Storage Connectivity stating “Lost path redundancy to storage device naa…….”. We had 2 fibre cards and one of the paths was being marked as down. I spent a couple weeks troubleshooting and trying different path selection techniques. Still, we would randomly get alerts that the redundant path has gone down. The only fix was to reboot the host, as not even a rescan would bring the path back up.
So after some trial and error, I found a solution. The RCA isn’t necessarily complete yet, but I believe it was a problem with the fibre switch having an outdated firmware and us using new fibre cards in our hosts. When using the path selection of Fixed, it would randomly pick an hba to use for each datastore. Some datastores would use path 2 and some would use path 4.
The solution I came up with was to manually set the preferred path on each datastore (we have about 40, so it was no easy task). You go into your host configuration, choose storage, pick a datastore and go into properties. Inside this window, select manage paths from the bottom right and you should see your HBA’s listed. There is a column marked Preferred with an asterisk showing which hba to prefer for the datastore (see the image below). I went through and manually set the preferred path to be hba2 instead of letting vmware pick the path. The path selection is persistent across reboot as well when setting it manually.
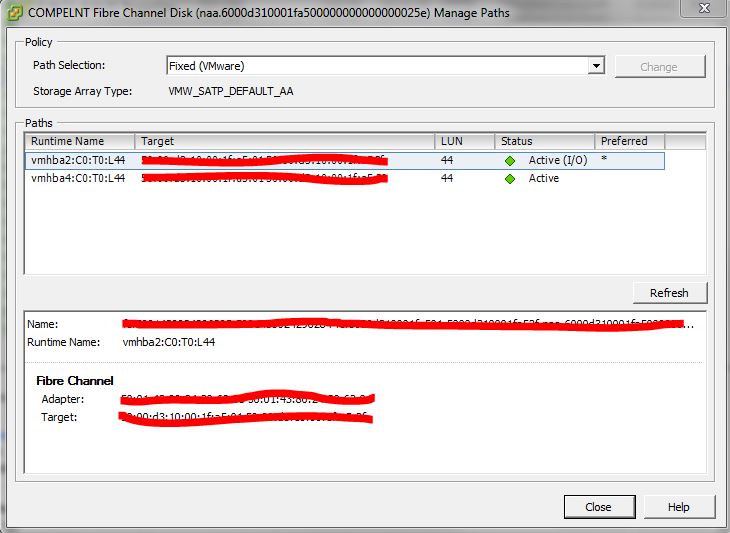 Since manually setting the preferred path, the hosts have been stable and we have not gotten any more errors about path redundancy. This is pretty much a band aid fix but at least we are not rebooting hosts 2-3 times per week.
Since manually setting the preferred path, the hosts have been stable and we have not gotten any more errors about path redundancy. This is pretty much a band aid fix but at least we are not rebooting hosts 2-3 times per week.