5 VMware Flings Worth Your Time (via Virtualization Review)

5 VMware Flings Worth Your Time
They’re free and useful, but not officially supported, so use with caution.
My Virtual Ramblings
5 VMware Flings Worth Your Time (via Virtualization Review)
They’re free and useful, but not officially supported, so use with caution.
VMware VSAN: When good enough more than passes muster (via The Register)
Last week I attended SFD9 and the last session of the week was with VMware about VSAN 6.2. This is not a review of the product or an analysis about single features; there are plenty of them already. Instead I’ll talk about what a product like VSAN 6.2 means for the entire SDS/HCI market.
Licensing Options for your vSphere Home Lab (via Wahl Network)
Looking to snag VMware licenses for your home lab adventures? Check out what I’m using, plus other options that don’t break the budget!
Let’s go over how to disable the “This host currently has no management network redundancy” message. It’s annoying and we can get rid of the yellow triangles that show on the hosts due to this message. And I know, you “should” have redundancy on your management network but we’re just not worried about it. Our hosts are in our building and not at a co-lo so we have constant access to them in the event something happens and we need access.
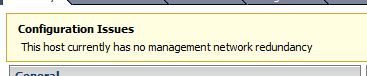 Since we don’t care about this warning, I wanted to hide it. This way we can see if there are actual errors on the host and not some warning about network redundancy. The fix is done with an advanced option in the cluster properties. In the cluster properties, under vSphere HA, select Advanced Options. Then add an option named das.ignoreRedundantNetWarning and set the Value to true.
Since we don’t care about this warning, I wanted to hide it. This way we can see if there are actual errors on the host and not some warning about network redundancy. The fix is done with an advanced option in the cluster properties. In the cluster properties, under vSphere HA, select Advanced Options. Then add an option named das.ignoreRedundantNetWarning and set the Value to true.
 And that’s it! Once the option is in, go to each host and reconfigure for vSphere HA. The warning will then disappear and your vCenter will look clean again.
And that’s it! Once the option is in, go to each host and reconfigure for vSphere HA. The warning will then disappear and your vCenter will look clean again.
Today when logging into the vSphere Web Client to document the SRM testing process, I noticed that the SRM plugin did not show on the home screen. However, when logging into the protected site I noticed that it was there. Here are my troubleshooting steps:
1. Logged into the SRM server and noticed the service was not running. I started the service and tried logging into the web client, but the plugin was still not showing.
2. I then rebooted the SRM box and logged back into the web client. Still no SRM plugin.
3. I restarted the vCenter service and web managementservices on the vCenter box. Still no SRM plugin.
4. Finally, I restarted the web client service on the vcenter box. Logged into the web client, and voila! Plugin was showing.
The root cause is that the SRM service must be running. If it is not, start the service and then restart the web client service on the vCenter server.
I had to redeploy a vCenter Server Appliance recently and got an error when opening vCenter: sysimage.fault.SSLCertificateError.
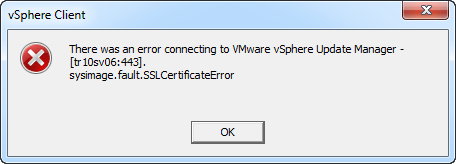 This is caused by the certificate on the vCenter Server changing. This causes the Upgrade Manager needing to be re-registered with the vCenter Server. Luckily, VMware provides a utility to do just that. Go to your vCenter Upgrade Manager Server (The appliance does not include this, so it will typically be installed on a separate Windows Server).
This is caused by the certificate on the vCenter Server changing. This causes the Upgrade Manager needing to be re-registered with the vCenter Server. Luckily, VMware provides a utility to do just that. Go to your vCenter Upgrade Manager Server (The appliance does not include this, so it will typically be installed on a separate Windows Server).
Go to “C:\Program Files (x86)\VMware\Infrastructure\Update Manager” and open the file “VMwareUpdateManagerUtility”.
 Next, enter the credentials for your vCenter Server and hit Login.
Next, enter the credentials for your vCenter Server and hit Login.
 Once the window opens, you’ll want to click “Re-register to vCenter Server”. This brings up another login screen. You can use the same credentials you did to open the utility here as well.
Once the window opens, you’ll want to click “Re-register to vCenter Server”. This brings up another login screen. You can use the same credentials you did to open the utility here as well.
 Finally click apply and you will receive a notification that you need to restart the VMware vSphere Update Manager in order for the settings to take affect.
Finally click apply and you will receive a notification that you need to restart the VMware vSphere Update Manager in order for the settings to take affect.
 Restart the service and open the vSphere Client again. The error will be gone and you’ll be able to use Update Manager again.
Restart the service and open the vSphere Client again. The error will be gone and you’ll be able to use Update Manager again.
A recent issue I was having was that our ESXi 5.1 hosts would go “out of sync” with the VDS. The only fix that would work was rebooting the host. After digging into the log file, I discovered that the host was failing to get state information from the VDS. The entries are below:
value = “Failed to get DVS state from vmkernel Status (bad0014)= Out of memory”,
}
],
message = “Operation failed, diagnostics report: Failed to get DVS state from vmkernel Status (bad0014)= Out of memory”
The issue is a bug in the version of 5.1 we were running (Update 2 at the time) and is a memory leak on the host when using E1000 NICs in your VMs. Because these VMs were created a long time ago, they were defaulted to the E1000. The fix for this issue is updating to the latest build of ESXi which has a fix for the issue. And also, don’t use E1000 NICs, always go with VMXNET3. Problem solved!
After installing 3 new hosts, I kept getting errors for Storage Connectivity stating “Lost path redundancy to storage device naa…….”. We had 2 fibre cards and one of the paths was being marked as down. I spent a couple weeks troubleshooting and trying different path selection techniques. Still, we would randomly get alerts that the redundant path has gone down. The only fix was to reboot the host, as not even a rescan would bring the path back up.
So after some trial and error, I found a solution. The RCA isn’t necessarily complete yet, but I believe it was a problem with the fibre switch having an outdated firmware and us using new fibre cards in our hosts. When using the path selection of Fixed, it would randomly pick an hba to use for each datastore. Some datastores would use path 2 and some would use path 4.
The solution I came up with was to manually set the preferred path on each datastore (we have about 40, so it was no easy task). You go into your host configuration, choose storage, pick a datastore and go into properties. Inside this window, select manage paths from the bottom right and you should see your HBA’s listed. There is a column marked Preferred with an asterisk showing which hba to prefer for the datastore (see the image below). I went through and manually set the preferred path to be hba2 instead of letting vmware pick the path. The path selection is persistent across reboot as well when setting it manually.
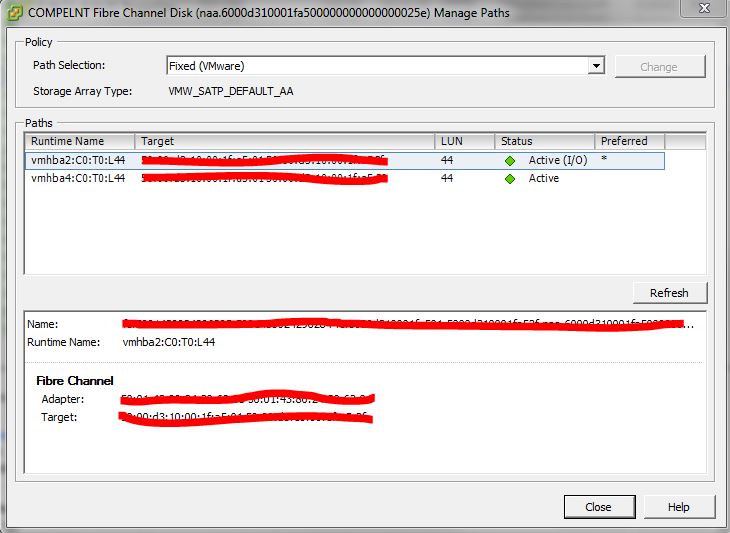 Since manually setting the preferred path, the hosts have been stable and we have not gotten any more errors about path redundancy. This is pretty much a band aid fix but at least we are not rebooting hosts 2-3 times per week.
Since manually setting the preferred path, the hosts have been stable and we have not gotten any more errors about path redundancy. This is pretty much a band aid fix but at least we are not rebooting hosts 2-3 times per week.
I recently had an issue where I was unable to remove a datastore from the vCenter Server Inventory. The datastore was grayed out and when right-clicking, had no options. After some digging and some research in SQL, I found a way to manually do this in the vCenter database. Every datastore is given a unique ID and can be found and removed inside of the database.
Warning: Always make a SQL backup before attempting any manual database changes. You never know when things might break and you need to restore.
So here we go:
select ID from VPX_ENTITY where name = ‘datastore_name’
delete from VPX_DS_ASSIGNMENT where DS_ID=ID;
delete from VPX_VM_DS_SPACE where DS_ID=ID;
delete from VPX_DATASTORE where ID=ID;
delete from VPX_ENTITY where ID=ID;
If you want to verify that everything went correctly, you can run the following:
select * from VPX_DS_ASSIGNMENT where DS_ID=ID; select * from VPX_VM_DS_SPACE where DS_ID=ID; select * from VPX_DATASTORE where ID=ID; select * from VPX_ENTITY where ID=ID;Now you’ve removed the datastore from the database and can start the vCenter Server Service again. If you don’t see that it has been removed, a reboot may help. I rebooted my server just to be on the safe side.
You can check out this VMware KB for more info.
A recent issue we experienced was seeing hosts disconnecting from vCenter and reconnecting. The host would drop and randomly come back for about an hour or more. The VM’s never saw any issues nor was there any type of outage. It was that vCenter could no longer see the host.
After quite a bit of troubleshooting, I started digging around in the vCenter Server Settings (Administration > vCenter Server Settings). In this menu, there is a tab for Runtime settings. I noticed that we only had the vCenter Server Name filled in and not the vCenter Server Managed IP. The window looks as follows:
 After completing all the fields in this window, the hosts magically all reconnected and have not dropped again. This is due to the fact that the hosts use these settings to check in with the vCenter box and they let the host know who it’s being managed by. As you can guess, if the host doesn’t know who’s managing it, it doesn’t know who to check in with.
After completing all the fields in this window, the hosts magically all reconnected and have not dropped again. This is due to the fact that the hosts use these settings to check in with the vCenter box and they let the host know who it’s being managed by. As you can guess, if the host doesn’t know who’s managing it, it doesn’t know who to check in with.
The more curious issue was that this field hadn’t even been filled out, but didn’t start immediately. Which made troubleshooting more difficult and made us all panic as we started getting numerous alerts for hosts dropping.
As best practice, whether you only have 1 vCenter server, is to fill out all these fields and enure they are correct. Especially if you want the host to check in with the correct vCenter server and you don’t want the heart attack of seeing numerous hosts suddenly disconnecting from vCenter.

